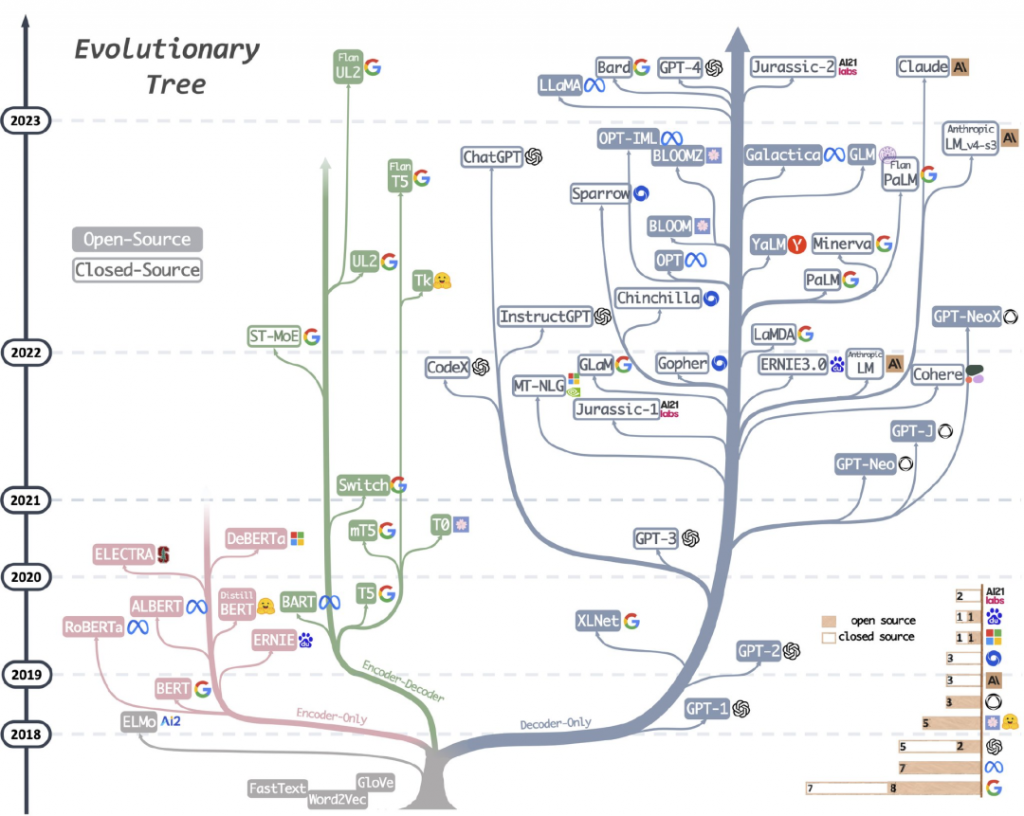
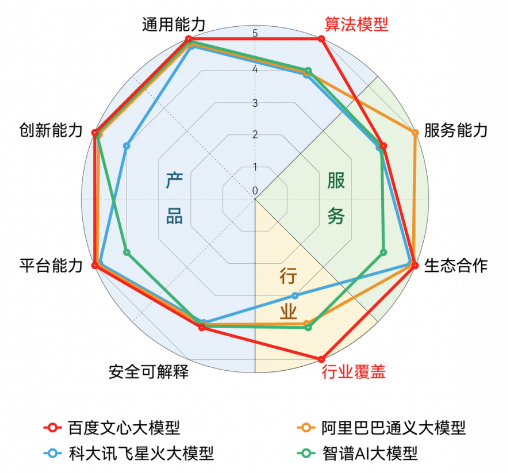
產品與服務

解決方案
客戶案例
關于樂思
聯(lián)系我們 400-603-8000
400-603-8000
400-603-8000