0x00 大規模系統下的威脅
隨著用戶數量、業務量的增長,互聯網企業的業務系統也變得越來越復雜,大量的訪問日志、龐大的代碼倉庫、數十萬或百萬計的IDC資產以及幾萬種開源組件構成了龐大的業務系統,但是隨之而來的是大量的威脅,體現在了可產生告警的設備數量非常大,使得產生的告警非常之多,并且部分告警是完全無效或者不可運營的。正是由于告警數量的龐大,安全運營團隊背負著巨大的心理壓力和負擔去處理,最后發現是個誤報或者說是個無意義的告警,久而久之安全運營就會疲于應付告警,這個時候一旦有攻擊出現,往往就會在很短的時間內失去整條防線,也就是經常說的一個段子:每年在安全上砸了一堆錢,但是實際上還是很容易被人家打進來了。龐大的資產、日志、流量,加上海量的不可運營的告警,也就間接對業務系統產生了大量的威脅。
通過對各種角度上的威脅進行梳理后,我們可以把整個互聯網企業可能面臨的安全威脅分為三大類,一類是以通用組件漏洞、僵木蠕為首的面向基礎設施的威脅,第二類是以業務系統缺陷、越權漏洞為代表的面向業務系統的威脅,第三類是以POI/UGC爬取、欺詐流量(也就是刷差評/好評的)等面向業務數據層面的威脅。有了威脅,才能去談威脅的情報。
在梳理完上述威脅后,筆者第一時間也去問詢了一些同行業的朋友,但是老朋友的反饋多為“買買買”,當然這個可以理解,因為最省事兒的方法就是買買買,但是仔細思考之后,筆者發現了“買買買”之后會衍生出來一大堆的問題,比如說如何評價威脅情報做的好不好,這也是筆者在接手威脅情報能力建設之后被老大挑戰的最多的問題之一;第二個問題似乎更現實一點,那就是威脅情報團隊的績效怎么去給,或者說如何評價威脅情報團隊的工作對整個安全建設工作是有實際意義的,這兩個問題其實在企業里面是常見但是不太好作答的問題。除了評價和KPI的問題,威脅情報本身由于先天的滯后性和本身的缺陷,也有很多不是很好解決的問題,由于問題多了所以便有了以下的段子。
首當其沖的是情報的準確性,很多情況下我們抓到一條情報之后,無從判斷真偽,更有的時候直接抓到了就直接定性是虛假情報了,這樣無形增加了很多的運營成本。第二個問題就是消息不對稱,很有可能情報從原始處獲取到了之后,由于生產的問題導致情報出現了失真,最后拿到手里是殘缺甚至是錯誤的情報,安全運營拿到了之后不知道如何處理這類的情報,在這里舉一個例子,在漏洞預警中,可能不小心沒有注意到告警描述里面的prior,導致了影響版本的誤判。
第三個問題其實更比較常見,我們買了很多IOCs、買了很多情報服務,數據量可能非常之巨大,但是實際上能拿來運營的往往就那么幾條。舉一個很常見的例子,我們在購買的IOC中只會提及IP是個掃描器、是個僵尸網絡,從來沒有人主動了解也沒有人去詢問他掃描了哪個端口,被哪個家族的僵尸網絡bot控制了,更有甚者會將一些公司的正常資產標記成惡意的,這個時候沒有人為威脅情報的結果負責,標簽就變成了無意義的話題。安全運營的同學見的多了自然就會對威脅情報產生了嚴重的質疑,再加上前面提到的安全運營會因為海量的告警出現了告警懈怠,導致真正有用的情報沒有能夠及時處理,讓真的威脅情報變成了”無效情報“,變成了為企業添堵。
最后就是情報的滯后,舉個很簡單的例子,就是通用漏洞的威脅情報。通用漏洞的情報很多時候都是看到朋友圈大量轉發或者群里大面積討論才知道有漏洞了,實際上這個漏洞很有可能是很早之前就發了修復補丁大家完全沒注意的。
再舉個很現實的例子,在今年7月12號的時候Squid(一款Web代理軟件,廣泛用于各大企業中)發布了一次安全更新,安全更新提到了包含認證、溢出等五個漏洞,CVSS評分最高6.8,但是到了今年8月底的時候,ZDI的一篇文章徹底引爆了這個漏洞,導致朋友圈瘋狂轉發,我們拋開這些告警來看,實際上這個漏洞已經有了一個月左右的窗口期,這就是典型由于消息滯后所導致的重要情報漏過,這個時候也會對企業的系統造成威脅。
這個時候,絕大多數都會想到,我們要去建立一套完整的威脅情報體系和運營流程,但是這個時候往往又會收到老板的連環追問:● 買了威脅情報服務是不是全接進來?
● 威脅情報數據質量是否有保證?
● 能不能及時產生有效的威脅情報通知或者工單?
● 工單有沒有人跟進閉環或者處理?
● 解決以后有沒有事后復盤等等問題接踵而至…看完這些你可能有點想放棄了,但是經過仔細考慮一下自己的KPI之后,你會發現買買買的方法并不能解決這些問題。所以這個時候你就會考慮構建自己的威脅情報能力了。
威脅情報的這一概念實際上是2013年被Gartner帶火的,Gartner對于威脅情報的定義是: 威脅情報是一種基于證據的知識,包括了情境、機制、指標、隱含和實際可行的建議。威脅情報描述了現存的、或者是即將出現針對資產的威脅或危險,并可以用于通知主體針對相關威脅或危險采取某種響應。就目前看,這一定義對整個威脅情報行業甚至是安全行業都有一定的指導意義,但是這一個定義的普適性很高,正是由于其普適性高的原因直接導致了我們在企業實際安全運營時候發現,Gartner所定義的威脅情報并不適用于實際的安全運營場景,原因是未對業務層面上的威脅進行定義。如果要建立一個完整的威脅情報體系,那么就必須要把業務系統、業務數據等業務層面的攻擊面以及閉環流程也納入進來,這樣的話我們對于針對企業各個層次上的威脅都有對應的威脅情報能力,這就是我們所認為的真實環境下應具備的威脅情報能力:能夠為發現潛在或已發生的威脅(包括但不限于業務數據、業務系統和基礎設施)提供有效且可靠的消息類型或者知識類型的數據,且該數據能夠通過安全運營進行高自動化的閉環處理能力,稱之為威脅情報能力,提供的數據稱之為威脅情報數據。
0x02 如何評價威脅情報能力建設的好壞
諸多血淋淋的案例和運營經驗告訴我們,威脅情報的能力構建不是簡單“買買買”就能搞定的,“買買買”不能解決實際的安全運營問題,這個時候我們就需要自己打造威脅情報能力體系了。但是在正式開始威脅情報的建設前,我們需要明確威脅情報能力的一個指標,也就是如何去評價威脅情報能力建設的好壞,我們通過內部的討論以及我們對于安全運營的經驗和實踐,為我們的威脅情報能力設置了四個比較現實的目標:低延時、高精度、可運營和能閉環。所謂低延時,目標是為了減少安全應急團隊的等待時間,縮短威脅響應的時間,并且盡量減少人工的介入,讓威脅情報能力能夠幾乎100%自動化的運營,減少因為人為原因而等待的時間,同時又保證有效情報的輸入和處理,所以自動化率和有效情報轉化率是在這部分需要關注的問題。
所謂高精度,指的是采集威脅情報數據的渠道足夠穩定,質量足夠高,來源足夠可靠,并且通過高準確度的算法來讓情報的精準度和內容豐富度達到可運營的標準及以上,這里就需要考驗情報生產算法和情報渠道的可靠性和穩定性,穩定的情報數據和渠道是高品質威脅情報的基石。
所謂可運營,是指我們的情報成品也就是FINTEL(全稱為是Final Intelligence,在情報界的表示交付的情報成品)的質量是否能夠高可讀、高可用同時具備閉環的特性,這個時候可操作性成為了評價這部分的指標。
最后就是能閉環,前面提到了情報如果不能夠運營和閉環的話,實際上就是無效情報,這個時候的考核指標可能就是閉環成工單的數量。
0x03 威脅情報生命周期和體系建設
在確定了清晰的目標之后,就應該開干了,我們在建設威脅情報能力體系的過程中,把整個威脅情報能力體系劃分成了四個部分:
1. 威脅情報數據
2. 情報生產工具
3. 情報管理平臺
4. 安全運營團隊
這也就是外界所說的人+數據+平臺的方式建設體系。
這里數據既包含了內部的諸如流量、日志、安全設備告警,也包含了外部的IOC、風控情報、第三方商業情報等外部情報數據,平臺這部分比較好理解,主要是為了提高運營效率,理想中的威脅情報平臺至少需要包含采集端、生產端和傳送端,其中采集端主要負責聚合各個來源的數據并且完成諸如分類、去除雜訊、去重等預處理工作;生產端負責的工作主要完成的事情是對威脅情報的修飾、加權分析、高階聚合操作,將威脅情報由預處理數據轉換成可用的情報成品FINTEL;而在傳播端則是將不同種類的情報成品FINTEL按照需求和運營方式傳遞給不同的人,完成后續運營和閉環的工作。截止到目前,我們在現有威脅情報體系中已經建成了一個基于威脅情報生命周期且兼容現有安全架構的威脅情報運營體系,同時建成了兩個情報平臺和三個數據庫,兩個平臺其中一個負責完成情報的閉環管理,我們叫它MT-Nebula,另一個完成情報按需推送,我們叫它MT-Radar,三個數據包含用來刻畫外部資產畫像、外部資產指紋數據庫,用來存放通用組件漏洞的漏洞信息數據庫,以及集成了公開IOC、自爬取情報和第三方商業情報的外部情報數據庫。在此基礎上,我們也建立了四個情報反饋渠道,包含人工、自動化、第三方和SRC,我們的SRC是既收漏洞也收情報的。
0x04 威脅情報的閉環與運營
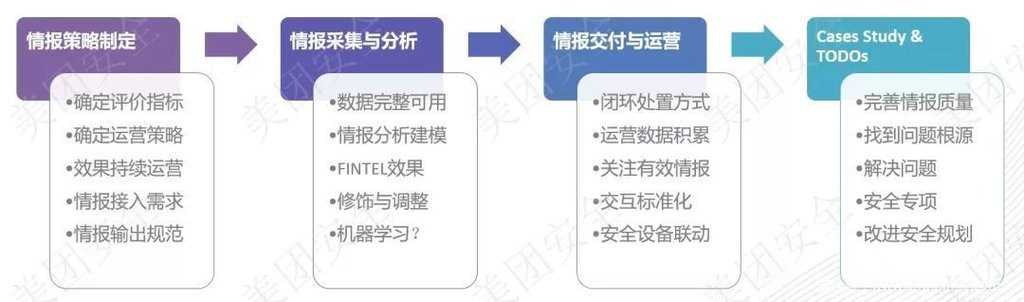
首先我們先來談一下企業的威脅情報生命周期,根據我們的業務特性和運營與閉環模式,我們根據實際的安全運營經驗和威脅情報的一些理論知識將威脅情報能力的運營和信息的閉環分為了四個階段,分別是:威脅情報策略制定、威脅情報采集與分析、威脅情報成品交付與情報運營和事后的復盤分析。
我們認為威脅情報能力應該是一個規劃導向的安全能力,并且威脅情報計劃是一個高度可操作的詳盡計劃,所以在日常的威脅情報工作中,我們對情報規劃這一部分看的很重,甚至一度認為沒有規劃后面做的很多東西可能都是錯的甚至是完全相悖的。在實際操作中,我們可能有35%甚至更長的時間和精力是在做一個可操作的威脅情報計劃,計劃的內容包含了評價的指標、不同類型情報的運營與閉環的策略、需要接入哪些類型的威脅情報、情報與資產數據的交互標準、交付規范等問題。好的規劃確實會事半功倍,同時也會讓運營效率更高。其次是威脅情報能力建設工作中技術含量最高的一部分,情報采集和分析,在這部分主要的工作點是數據完整性確認、情報數據預處理、分析建模、精加工和修飾調整。目前從效果來看的話,在粗處理階段引入機器學習的分類方法,會使后期情報數據精加工的工作變得異常容易,但是在精加工階段,機器學習又顯得非常”添亂“,一方面是因為客戶的需求眾口難調,另一方面是準確度的問題。在精加工完畢后,我們需要對FINTEL添加佐料,佐料的作用是為了后面增加情報的可運營性。
下一步進入了一個非常重要且非常難做的環節,威脅情報成品的交付和運營。如果前面做了詳實且可執行的威脅情報計劃,在這里就變得輕松了許多,按部就班按照計劃執行即可,需要考察威脅情報的準確性和閉環成工單的數量,威脅情報運營手段與其他的安全運營手段相比沒有什么特殊之處。
最后一個階段就是威脅情報運營結果的復盤和總結,這部分主要是為了解決情報反饋出來的問題,也就是所謂的“分鍋大會”,這一點往往是情報產生實際價值的時候。值得注意的是,情報的計劃可能會隨著多個case的積累而發生改變,并且解決問題不應該是追責,而是應該閉環。
當我們完成了對威脅情報能力生命周期的構建之后,下一步就是基于這一部分周期來設計一個完整的威脅情報體系。在設計這一部分體系的時候,首當其沖要考慮的應該是威脅情報體系應當兼容現有的安全體系,其次,要完全按照情報的生命周期逐漸累加必要的數據和分析方法,最后將這些能力和威脅情報生產算法平臺化和規范化。
我們在經過一段時間的運營和實際的應用的結果來看,結合我們現有的安全能力和體系,我們的威脅情報體系如下圖所示,該體系分為了五個層次,分別對應上文中威脅情報生命周期中的四個環節,規劃部分對應策略制定環節,數據研判、情報處理、情報分析對應采集與分析環節,情報運營、閉環處理和復盤分析分別對應情報運營環節。
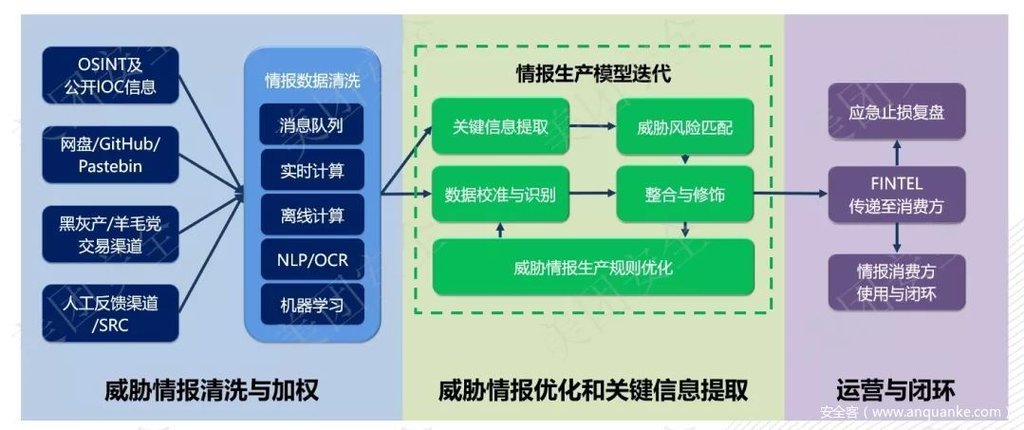
在情報規劃階段,我們需要考慮的內容是我們會面臨何種類型的威脅、我們如何去收集發現這些威脅所對應的威脅情報、收集到的威脅情報如何加工成我們想要的FINTEL成品、成品如何交付和運營、閉環策略分別是什么等問題。緊接著就是數據研判,所謂數據研判第一件事情是先確認內部的數據是否完整、可用,因為內部數據的不可用很有可能會影響后面的數據交叉分析,除此之外,外部情報也要保證按照事先的情報計劃接入對應的數據,保證數據是充足的,我們在綜合了業務安全情報和基礎安全情報后,優先考慮接入了黑產情報渠道監控、Github監控和人工反饋渠道,而老生常談的IOCs、OSINT數據、第三方商業情報數據甚至是我們自己構建的指紋數據庫,則以API的形式對外提供檢測服務,允許其它安全設備接入獲取對應的數據,達到為安全賦能的目的,同時我們允許人工反饋情報,實現現有情報源的有機補充。
當數據準備完畢后,接下來就是情報數據的預處理環節,預處理需要解決的問題包含:情報來源格式不統一的問題、情報來源不可信的問題、情報素質低的問題、情報重合的問題等,在經過預處理后,我們將會得到一個具備初步可分析條件的威脅情報數據,成為粗產品。
在拿到粗產品后,我們需要對粗產品進行進一步的精加工,其目的是為了保證情報滿足我們最初設計的目標,達到目的和效果。在經過分析后,我們就會得到完整的情報FINTEL成品。
緊接著我們在得到FINTEL成品后,會通過各種形式讓情報進入運營狀態,這些形式不拘泥于表象,包括但不限于工單、信息推送等。同時在這里,平臺化的能力沉淀就顯得十分重要。到此,我們的情報能力矩陣就介紹完畢。
0x05 情報分析技術探秘
以上內容讓我們對情報體系有了一個初步的了解,但是作為技術能力最強的分析,我們需要詳細闡述一下情報的分析過程,為了方便大家的理解,我會以漏洞情報作為例子來闡述一下具體的操作,整體流程如下圖所示:
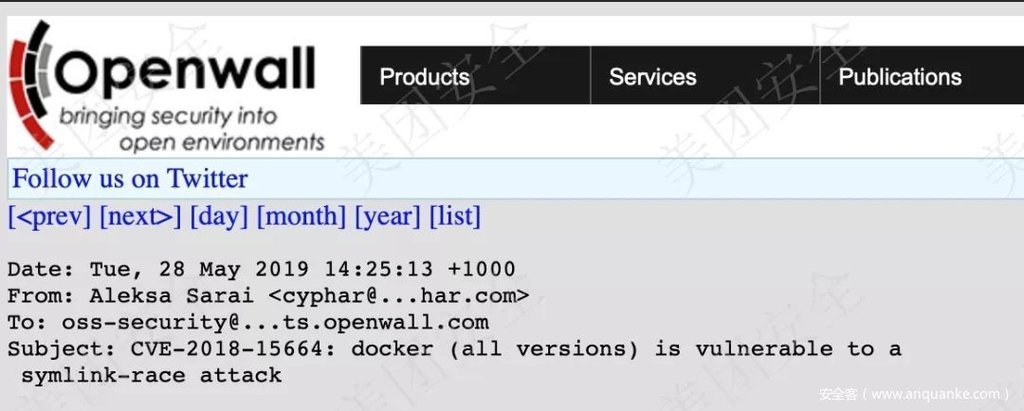
首先在一條情報進來之后,他可能是多種形式,可能是一個微信群聊的截圖、一篇新聞,也有可能是一條Twitter,大概率也可能是一個很豐滿的JSON數據,至于STIX、TAXII、CyBox這種也會存在,那么這個時候我們就需要將這些數據通過各種方法整合成我們大概能看懂的一個粗產品。我們以漏洞情報為例來說明,當我們拿到一個原始的漏洞數據的時候,他可能是一個GitHub上的issue,也可能是一封來自于Openwall的郵件,更有可能是某個群里一句話,通過絕大多數的實驗和實際場景,我們認為郵件是一個比較好的切入點,因為既包含了issue又包含了openwall的列表,所以我們往往會以郵件作為重要的情報來源之一。在獲取上述情報來源后,需要對情報進行初加工,這一部分依賴的技術主要是OC
R技術和NLP技術,OCR技術的作用是用來識別圖片中的文本信息,提取出其中的文本,達到了圖片轉文字的效果,在這一部分處理后,我們剩下的多為文本情報了,這個時候NLP技術將會幫助我們提取其中的關鍵信息如詞性、詞頻等,比如說專有名詞、時間等,獲取到這些信息之后,我們將會把這些分析結果向量化,使用機器學習方法(如目前的機器學習網紅算法XGBoost)對這些詞進行聚類,然后通過自己訓練的模型將關鍵信息分類,整理到一條數據結構中。
對于我們的漏洞而言,在上一步獲取到源數據之后經過上面提到的方法,我們整理出了以下內容,當然內容不完全正確。很明顯這個時候情報仍然是不可用的,因為雖然有了漏洞信息,但是情報仍然不可
讀、不可用,這個時候我們就需要通過其他的情報進行交叉填充,完成對情報數據的補充,如上面提到的漏洞,詳情可以通過MITRE和NVD的官方數據庫獲取詳情。
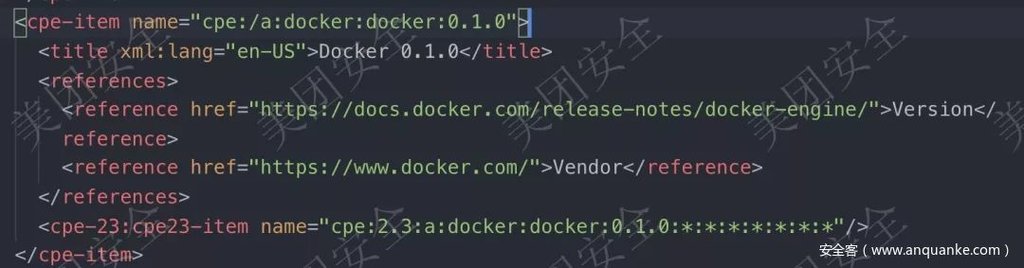
由于我們獲得了版本號,所以在CPE數據或者SWID數據中,我們可以拉取對應廠商對應產品下該版本的所有分支版本,這樣就可以獲得完整的影響范圍。
另外我們也可以從官方公告中獲取CVSS數據,來輔助判斷影響范圍。
這個時候,我們大概就得到了一個詳實的數據結構,但是這仍然不是我們想要的FINTEL,這部分只能作為情報的粗加工產品,傳遞至精加工的流程。
在我們拿到粗加工的情報產品后,我們會和內部數據進行交叉分析,同時引入數據的校準機制,目前這部分工作絕大部分依靠人工,少部分依賴正則表達式,同時我們還會對情報封裝快捷操作和功能,將一些必要的英語通過翻譯API翻譯成中文方便運營的理解,并且通過不同的影響范圍,人工或者自動地調整情報成品中各個情報源的比重來完善這一情報生產模型,這一過程稱之為情報生產模型的迭代,再經過人工修飾后,我們就得到了情報的FINTEL成品。一個好的FINTEL必須滿足以下條件:保證情報內容可在短時間之內讀懂,所有評估所需要素一應俱全,提供閉環所需解決方案,影響范圍一目了然,方便后續運營閉環操作。當然同類型FINTEL的交付模式應有對應的交付驗收,以保證情報FINTEL滿足運營團隊的運營需要。
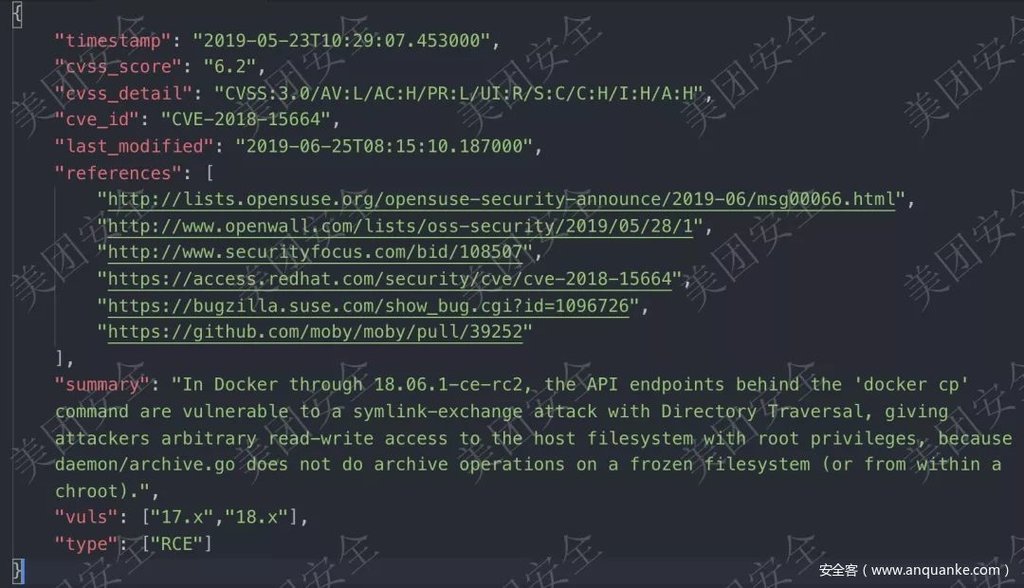
接著上面的漏洞情報,我們最終交付的情報成品是這樣的。通過上述的運營方式,我們一般可以最少提前行業內的預警十幾個小時獲知此漏洞的存在,目前獲取的最長時間差為7天時間。
0x06 威脅情報與安全設備的聯動
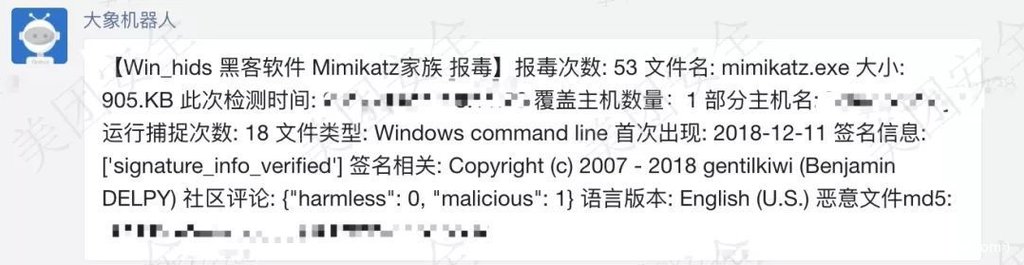
生成的威脅情報成品如果還有包含信譽類檢測的功能,我們應當保證這些功能是被安全設備調用的,這也是威脅情報賦能的一種表現。企業內部的安全產品如果按照生產環境和辦公環境劃分的話,生產環境的三大件是IDS、WAF和防火墻,辦公環境的三大件是DLP、EDR和郵件網關(絕大多數EDR廠商的前身都是殺軟廠商,所以殺軟和EDR在好的產品中應該是打包的)。對于各自的三大件,情報的賦能限于檢測和查詢,如以下的告警則是和HIDS進行聯動的應用場景。
當然業務層面上的情報,除了與反爬系統聯動之外,最好的應急方式是拉群定損,這個時候情報的評價就會體現在快不快上,因為快意味著損失會少,產出會更明顯一些。
0x07 summary
在龐大的復雜系統下去干威脅情報,難度不亞于刷王者級副本,從獲取威脅情報到完全閉環一個告警是一個極其困難且有很大挑戰的過程。雖然很多企業在構建威脅情報的時候都不約而同的選擇了以買買買為核心的情報能力構建,但是一直“買買買”實際上不能解決“未運營的威脅情報不會產生任何使用價值”的問題。其實威脅情報能力對于企業安全的價值最重要的兩點是減少信息不對稱帶來的損失、賦能于安全提高威脅發現率。但是由于行業內各家對于威脅情報的理解和看法都不盡相同,所以在威脅情報具體落地實施的情況下都是各走各的路,各有千秋。但是我們始終認為威脅情報是規劃導向的產物,在實際威脅情報運營和閉環中,我們發現很多問題在規劃階段就可以完全避免這一類問題的發生。所以在構建企業級威脅情報能力的時候,往往坑在規劃,重在生產,難在運營,結果取決于閉環的結果。
但是即使做好了,在面對考核和評價的時候,往往也要給自己定一個小目標,也就是評價威脅情報能力好不好的四大標準:速度快、情報準、可運營、能閉環。有了體系,就需要將能力沉淀下來,構建人+平臺+數據的解決方案,在威脅情報體系建設中,情報體系、自動化平臺、數據資源、獲取渠道都是會影響威脅情報能力的關鍵指標,過程不重要,在結果導向的環境下,FINTEL的好壞才是成敗的關鍵,因為FINTEL的好壞直接決定運營難度,好的FINTEL需具備易讀懂、可操作、能運營的特性,讓運營同學一看就能用。
雖然各家對于威脅情報的看法不盡相同,但是希望這篇文章闡述到的觀點能夠成為一個可供同行參考的模型,這才是真正意義上的威脅情報為行業賦能。
信息來源:網絡
圖片來源:網絡
如有侵權請聯系刪文

 400-603-8000
400-603-8000