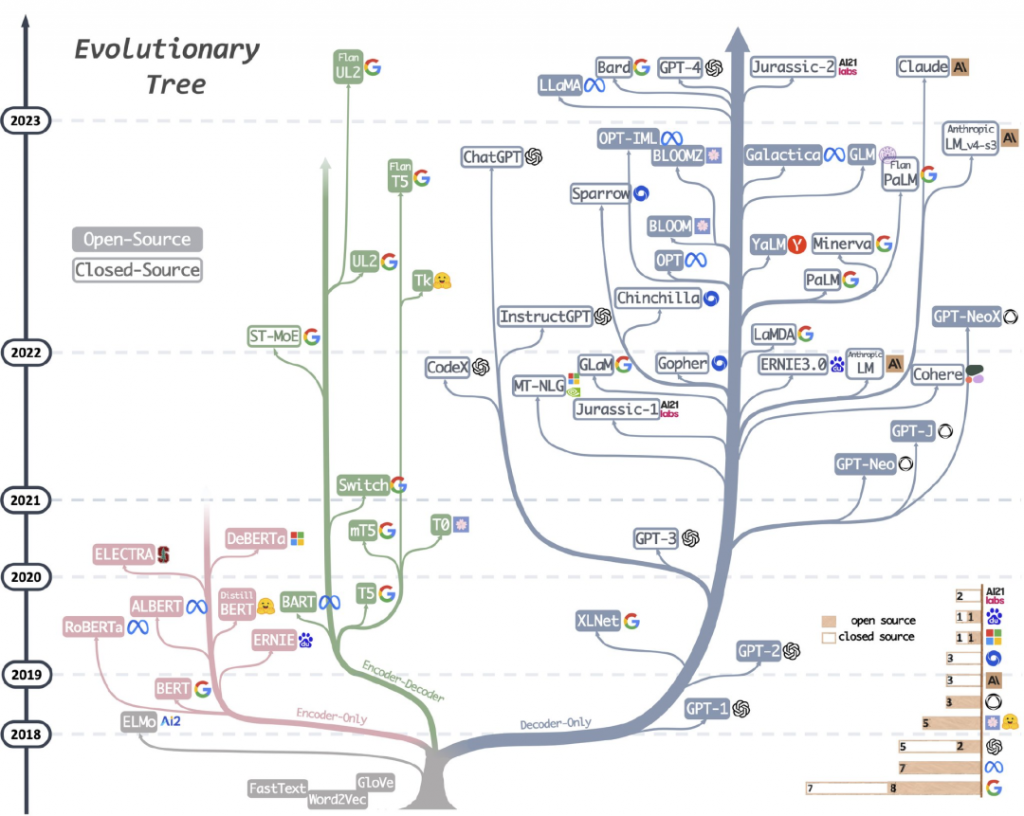
一、GPT-4最強競品Claude 2發布
具有更強的代碼能力!更長的上下文!免費!
近日,Anthropic公司發布了他們最新的模型Claude 2,支持200,000 token,可免費使用。
Anthropic公司是由OpenAI前研究副總裁Dario Amodei等人在2021年創建,該公司還得到了谷歌、Salesforce和Zoom等公司的投資,目前估值為 41 億美元。今年5月,Anthropic便是受邀參加白宮會議的四家人工智能公司之一,其他三家分別為谷歌、微軟和OpenAI。
Claude 2 相對于ChatGPT的優勢——
1、Claude 2 比 GPT-4 便宜5倍。
2、Claude 2 有更新的數據。這些數據是網站、第三方授權的數據集以及2023年初用戶自愿提供的數據的混合。
3、Claude 2 在 GRE 寫作和 HumanEval 編程基準測試上表現優于 GPT-4。
4、Claude 2 上下文窗口有100,000個token,是所有商業模型中最大的。
5、Claude 2 可以分析大約75,000個單詞,大約是一本書的長度;相比之下,ChatGPT 可一次性處理 3,000 個單詞的文本,而 GPT 4 則可以處理 25,000 個單詞的文本。
6、Claude 2 可以輕松處理任何與代碼相關的任務。
網友實測Claude 2 的代碼功能:

網友實測Claude 2 的文檔總結功能:
Claude 2技術論文:https://arxiv.org/abs/2212.08073
二、開源大模型Llama 2可直接商用
一直以來 Llama 可以說是 AI 社區內最強大的開源大模型。但因為開源協議問題,一直不可免費商用。7月19日,Meta 終于發布了免費可商用版本 Llama 2。
此次 Meta 發布的 Llama 2 模型系列包含 70 億、130 億和 700 億三種參數變體。相比于 Llama 1,Llama 2 的訓練數據多了 40%,上下文長度也翻倍,并采用了分組查詢注意力機制。具體來說,Llama 2 預訓練模型是在 2 萬億的tokens 上訓練的,精調 Chat 模型是在 100 萬人類標記數據上訓練的。

在幾乎所有基準上,Llama 2 70B 的結果均與谷歌 PaLM (540B) 持平或表現更好,不過與 GPT-4 和 PaLM-2-L 的性能仍存在較大差距。

Llama 2技術論文:
https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
三、華為盤古大模型3.0發布
7 月 7 日,在開發者大會 2023(Cloud)上,華為重磅發布盤古大模型 3.0,將圍繞行業重塑、技術扎根、開放同飛三大創新方向,為行業客戶、伙伴及開發者提供更好的服務。

模型聚焦三層架構,賦能千行百業——
L0 層包括NLP、視覺、多模態、預測、科學計算五個基礎模型,提供滿足行業場景中的多種技能需求。盤古3.0 提供了100 億、380 億、710 億和1000 億參數等基礎大模型,以匹配不同場景、時延、響應速度的行業多樣化需求。
L1 層是多個行業大模型,華為云既可以提供使用行業公開數據訓練的行業通用大模型,包括政務,金融,制造,礦山,氣象等大模型;也可以基于行業客戶的自有數據,在盤古大模型的L0 和L1 層上,為客戶訓練自有的專用大模型。
L2 層提供了更多細化場景的模型,更專注于政務熱線、網點助手、先導藥物篩選、傳送帶異物檢測、臺風路徑預測等具體行業應用或特定業務場景,為客戶提供“開箱即用”的模型服務。
四、國內大模型能力對比
7月19日,IDC發布《AI大模型技術能力評估報告,2023》,IDC對其中9家技術服務提供商進行了技術評估,分別為阿里巴巴、百度、第四范式、科大訊飛、瀾舟科技、云從科技、智譜AI、中國電信智科以及中科聞歌。
9家大模型技術能力綜合評分:

另外,百度文心大模型、阿里巴巴通義大模型、科大訊飛星火大模型、智譜AI大模型在通用能力上表現滿分。“通用能力”指標反映的是大模型的整體技能,包括語音識別、語音合成等自然語言處理;圖片生成、圖片搜索等計算機視覺;機器學習/深度神經網絡等底層技術能力的差異化優勢;意圖識別、泛化能力、知識庫構建能力等。
主流大模型各項指標評分:
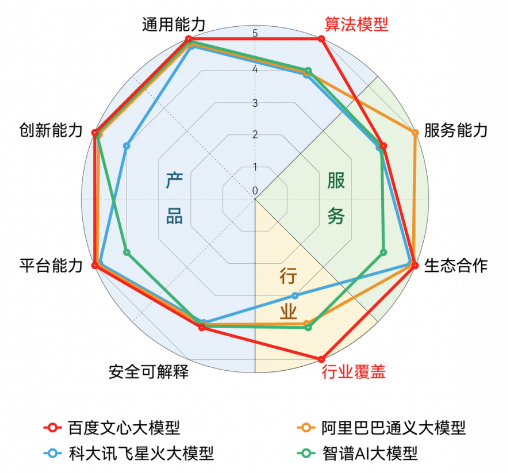
早前,沙利文根據AI大模型在產品技術能力、戰略愿景能力、生態開放能力三個維度的綜合表現對比相關廠商的綜合競爭力,評分靠前的依次為商湯(SenseCore 商湯 AI 大裝置 + 商湯日日新 SenseNova大模型體系)、百度(AI 大底座+文心大模型)、阿里(M6-OFA +“通義”大模型)、華為(ModelArts + 盤古大模型)、騰訊(HCC 高性能計算集群+混元大模型):

近日,谷歌旗下DeepMind在Nature上,發表了最新的研究成果“Faster sorting algorithms discovered using deep reinforcement learning”:AlphaDev作為一個全新AI系統,成功將一種每天運行數億萬次的C++排序算法的速度提高70%,同時,對于哈希算法,也找到了速度提高30%的辦法,超越了科學家們幾十年來的研究;甚至在部分算法上,能夠比人類快3倍左右。

DeepMind CEO Hassabis表示:“AlphaDev發現了一種全新且更快的排序算法,我們已經將其開源至C++庫中供開發人員使用,這僅僅是AI被用于提升代碼效率的開端。”
這項成果的重要性,正如Google DeepMind研究科學家Daniel J. Mankowitz所說:“我們估計,AlphaDev發現的排序和哈希算法,在全球范圍內每天被調用數萬億次。”
AlphaDev所發現的最新成果,被納入LLVM標準C++庫Abseil并且開源,供開發者運用。十幾年來,C++排序庫首次更改,AI在其中發揮了里程碑的作用,數十億人將會受益。
(二)AMD推最強AI芯片 單個GPU跑大模型
近日,AMD發布AMD Instinct MI 300X,一款專門面向生成式AI推出的加速器。AMD Instinct MI 300X采用8 個 GPU chiplet(基于CDNA 3架構)和另外 4 個 IO 內存chiplet的設計,這讓其集成的晶體管數量達到了驚人的1530億。而為了緩解AI 大型語言模型 (LLM) 所面臨的內存制約,AMD為這款芯片集成了192GB的HBM 3,其存儲帶寬也高達5.2 TB/s,可以處理的參數高達400億。

作為一款對標英偉達H100的產品,AMD Instinct MI 300X的HMB密度是前者的2.4倍,帶寬則為前者的1.6倍。這讓AMD的這顆產品在當前的AI時代競爭力大增,為 AI 推理和訓練提供不一樣的解決方案。據AMD介紹,該芯片會在今年三季度送樣。
]]>1、輿情對比
1.1 GPT-4
1.1.1 太太強了
北京時間3月15日凌晨,OpenAI發布了ChatGPT的最新版本——GPT4模型,OpenAI的CEO Sam Altman介紹說:這是我們迄今為止功能最強大的模型!
GPT-4是一個超大的多模態模型,它的輸入可以是文字(上限 2.5 萬字),還有強大的識圖能力,不僅回答的準確性顯著提高,而且會寫代碼、做網站、報稅、總結文章、寫詩,在部分專業測試和學術基準上,表現出了與人類相當的水平。
GPT-4的發布引起了全球范圍內的熱烈關注,比爾·蓋茨稱一生所見的兩次革命性技術就是1980年的圖形用戶界面和2022年的ChatGPT,認為ChatGPT不亞于PC和互聯網的誕生。
國內商界也一致看好,繼王慧文(前美團聯合創始人)、王小川(前搜狗CEO)后,李開復也入局AI大模型賽道,籌建Project AI 2.0,“AI 2.0不僅僅是個高能聊天工具,也不僅僅是圖文創作的AIGC生成,Co-pilot和如今看到的應用都還只是AI 2.0能力的開端”。
國內媒體大多也以積極正面的態度報道,典型的媒體新聞有:
量子位:《ChatGPT大升級!太太太太強了!》
澎湃號:《ChatGPT4發布,我真的慌了!》
網易號:《ChatGPT-4震撼發布!準確性提高,能在SAT上能擊敗90%人類》
新京報:《GPT4功能強于ChatGPT 還能識圖和角色扮演》
電腦報:《ChatGPT-4重磅發布,10秒做出一個網站,全面碾壓上一代》
1.1.2 職業焦慮
(1)高盛:AI或致全球3億人“丟飯碗”!
高盛研究發現,ChatGPT等生成式人工智能系統的最新突破,料將給全球勞動力市場帶來重大顛覆,全球預計將有3億個工作崗位被生成式AI取代,律師和行政人員將是最有可能被裁員的崗位。
目前歐美約有三分之二的工作崗位都在某種程度上受到AI自動化趨勢的影響,而多達四分之一的當前崗位有可能最終被完全取代。該研究計算出美國63%的工作暴露在“AI影響范圍”中,其中7%的工作有一半以上的流程可以由AI自動化完成,這使他們很容易馬上被人工智能取代。在歐洲,情況也差不多。
(2)網友
看到ChatGPT各種強大的功能,許多人擔心自己的職業會被替代。

1.1.3 信息泄露
(1)事件
3月24日左右,由于一個開源庫中的錯誤,導致一些ChatGPT用戶可以看到另一個活動用戶聊天歷史記錄中的標題,而且新創建的對話的第一條消息也有可能會在另一個用戶的聊天歷史記錄中可見。另外,同樣的錯誤可能會導致1.2%的 ChatGPT Plus 訂閱用戶在特定的九個小時時間窗口內意外地看到與支付相關的信息。
(2)公司回應
該漏洞是在Redis客戶端開源庫redis-py中發現的,OpenAI一發現該漏洞,就向 Redis 維護者發送了一個修復問題的補丁;并向其用戶和整個ChatGPT社區道歉:表示漏洞已被修復,完整的信用卡號碼在任何時候都沒有暴露,將努力重建信任。
圖 OpenAI道歉聲明的部分截圖

(3)媒體觀點
媒體觀點中最具代表性的是新京報發布的《把數據交給人工智能前要先保證安全》:
ChatGPT泄密事件是一種警示:再先進的新技術,如果存在安全后門,則應用越廣泛、帶來的不可控風險越高。因此,無論是技術開發方和使用方都要高度重視其安全體系建設。希望ChatGPT成為人類發展之福,而不是打開了潘多拉盒子。
(4)網友觀點
就此事而言,大多數網友表示國內又用不了,有bug也與自己無關:


1.1.4 倫理風險
人工智能的倫理問題討論一直伴隨著人工智能的發展,最具代表性的媒體觀點是近日中國經濟新聞網發布的《人工智能倫理問題及趨利避害思考》:
“目前,ChatGPT類的大語言模型人工智能技術及產品風生水起,帶來已知倫理風險主要有以下幾個方面:一是AI抄襲風險,二是信息泄露風險,三是未成年人保護風險,四是價值觀滲透風險,五是勞動者失業風險,六是惡意改造風險。”
1.2 文心一言
1.2.1 發布會引熱議
1.2.1.1 事件輿情
北京時間3月15日凌晨,OpenAI發布GPT4之后,壓力全部給到百度這邊,大家期待文心一言能否與之一戰?作為全村的希望的百度不負眾望在3月16日按期發布了大模型文心一言,百度CEO李彥宏現場展示了文心一言在文學創作、商業文案創作、數理推算、中文理解、多模態生成五個使用場景中的綜合能力。
然而,由于前期的高調宣傳給大家太高期望,而文心一言目前的功能似乎不能滿足大家的期待;而且由于現場是PPT視頻演示對話,而不是現場直接調用大模型給出答案,引發大家猜測和質疑,甚至被網友調侃為 “ChatGPT” VS “ChatPPT”。
圖 網友調侃文心一言的功能不及預期

也有網友看好百度,比較典型的觀點:
“如果把OpenAI比作大學生,那么文心一言可能還是小學生。我相信經過大量的訓練,文心一言也能成長得非常出色。盡管現在還不完美,百度還信守承諾把文心一言給推出來了,就沖著這份魄力與決心,作為首個中文類ChatGPT產品,我認為是值得鼓勵的。畢竟除了百度,其他大廠都還停留喊口號的階段。”
總的來說,文心一言發布會后的輿論情況分布如下:

1.2.1.2 公司回應
實際上,李彥宏在發布會一開始就承認現在還有差距:“大家的期望值,是我們對標ChatGPT,對標GPT-4,這個門檻有點高。十月懷胎,我們就帶大家來看看這個AI大模型文心一言長什么樣。”
李彥宏事后表示,文心一言雖然還有不少不足之處,但是他為百度團隊能夠在全球大廠中率先推出這樣一個產品感到驕傲,因為市場需求太旺盛了,無數的客戶都想盡快試用和合作。
1.2.2 文生圖再引熱議
百度開放一些賬號,讓用戶可以參與文心一言的測試,只需在線輸入詞語,即可繪制相應的圖像,然而,出現了很多意想不到的結果,用戶紛紛在社交平臺質疑和調侃。

1.2.2.1 疑似套殼
有微博大V質疑:“文心一言恐怕是和漢芯、鴻蒙一樣的東西:套殼、畫皮、造假。”

比如,讓文心一言生成一幅“總線和狗”的圖片,結果卻創作出了一張公交汽車和狗的照片。因為英文的“bus”有公交車和總線的意思。

于是,網友認為文心一言只是把中文句子翻譯成英文,再拿到國外開源的人工智能(Stable Diffusion)上畫圖,然后再將圖片返還給用戶,完全就是個“套殼、畫皮、造假”的人工智能。
一時間引起廣大網友群嘲:
“人家一開源,這邊就開始自主創新了,做的還不行。”
“底層就是國外的開源代碼,原封抄過來套了個殼子,就是國產研發了。”
“就是翻譯+stable diffusion,太明顯了。”
“這畫風一看就是國外的。”
也有網友反對爆料博主的觀點:
“哎吆他一個網紅,百度有沒有連夜公關買斷。你連一個代碼都不會敲的人怎么有臉說人家鴻蒙是套殼、畫皮、造假。”
“很多人不會理解的,因為他壓根不知道你說的是什么。就好像你用牛頓-萊布尼茲公式算積分,他也會認為你抄襲,為什么要用外國人的方法呢。”
“有這個自研的想法和行動力還是值得尊重的。”
1.2.2.2 文心一言自爆
在對話文心一言,詢問其是否采用Stable Diffusion(國外開源的人工智能)時,文心一言不僅承認使用Stable Diffusion,還承認使用Transformer、GRU等深度學習模型來生成圖像,并非完全自研。

1.2.2.3 沒有套殼
也有冷靜的網友認真分析了背后原因,認為百度的畫圖AI采用了英文標注的開源圖片素材進行訓練,因此需要中翻英來當提示詞。目前還沒有上億規模中文圖文數據集。即使有,噪聲也很大,基本不可以用。行業內都是用國外數據集,做中文映射,才導致這樣的生成效果。
所以,所謂“套殼”、“作假”等恐怕是大眾對文心一言的誤解。
1.2.2.4 腦洞太大

一些網友的評論充滿調侃的意味,也有一些網友認為真是腦洞大開,可以帶來不一樣的文字理解視角;另有些網友純粹覺得這個功能很幽默、很好玩:
“這是出來搞笑的吧”
“欺負AI不懂成語”
“中方負責人工 西方負責智能 沒毛病”
“確實感受到了歡樂,唐伯虎點秋香,胸有成竹的壯士,哈哈”
“腦洞大開,看著有點想笑[笑cry]”
“網友快把文心一言逼瘋了”
1.2.2.5 正面評論
有許多網友沒有跟風嘲諷或調侃,而是力挺百度,一些典型觀點如下:
“盡管是困難重重,但百度作為全世界第一家站出來挑戰ChatGPT的中國民營企業,精神確實可嘉。”
“不要太苛刻了,國內要有自己的技術。”
“國內技術看百度這句話的確沒錯,多給點時間吧。”
1.2.2.6 百度回應
1、官方回應
3月23日,百度在微博表示,已注意到對文心一言文生圖功能的相關反饋,并回應說明如下:
(1)文心一言完全是百度自研的大語言模型,文生圖能力來自文心跨模態大模型ERNIE-ViLG。
(2)在大模型訓練中,我們使用的是互聯網公開數據,符合行業慣例。大家也會從接下來文生圖能力的快速調優迭代,看到百度的自研實力。
百度方面還稱,文心一言正在大家的使用過程中不斷學習和成長,請大家給自研技術和產品一點信心和時間,不傳謠信謠。
2、高管回應
百度副總裁袁佛玉在朋友圈曬出了用文心一言制作的AI繪畫。暗示百度已經修正了一些bug。

2、輿情數據對比
2.1 輿情走勢

樂思輿情監測系統顯示,自3月15日GPT-4發布開始,全網有關OpenAI的輿情聲量就一直維持在22000-52000篇的高位,熱度非常高。
百度于3月16 日發布文心一言,全網聲量在3月16日和17日達到頂峰約15000篇,之后的輿情高點逐步走低至約10000篇左右;即文心一言的輿情高點還不及OpenAI的輿情低點。
另外,3.14-3.29期間,OpenAI的日均輿情聲量為37591篇,文心一言的日均輿情聲量為7499篇,只有前者的20%。所以輿論對ChatGPT的熱度遠超文心一言。
2.2 媒體類型
2.2.1 媒體類型數據比例圖

樂思輿情監測系統顯示,3.14-3.29期間,ChatGPT和文心一言在各媒體渠道的信息總量分布比例如上所示。
兩者微信和論壇的信息占比差不多:ChatGPT和文心一言的微信信息占比分別為17.7%和16.7%,兩者在論壇的信息占比分別為10.3%和11.6%。
而ChatGPT在微博信息占比為12.3%,高于文心一言的9.9%。ChatGPT在APP信息占比為9.3%,低于文心一言的13.0%。
2.2.2 網站關注度排行

樂思輿情監測系統顯示,3.14-3.29期間,信息量最高的前八大網站如圖,ChatGPT和文心一言關注度最高的兩大網站都是微信公眾號和新浪微博;ChatGPT在各網站上的關注度都比文心一言高。
2.3 熱詞云圖
從樂思輿情監測系統解析的云圖來看,ChatGPT的熱詞為“ChatGPT”、“人工智能”、“模型”、“科技”、“技術”等,文心一言的熱詞為“文心”、“百度”、“一言”、“模型”、“人工智能”等。人工智能、模型都是兩者的熱詞。
圖 ChatGPT的熱詞云圖

圖 文心一言的熱詞云圖

3、實力對比
3.1 功能
根據國金證券的測試研究,三大模型在客觀問題問答方面都有出色表現,但在數學計算、代碼生成、情感理解和推理方面均有待提升。對比來看,文心一言在圖像創作、歸納總結等問題中表現較為出色,但在邏輯推理領域還有待加強。在具體應用中,三大模型均能基本勝任 AI 助手、售后客服、產品推薦等場景需求,但在文本修飾及古詩詞理解領域仍有提升空間。
圖 “文心一言”與ChatGPT測評結果對比

如,回答一個代碼題:
“用 Python 編寫一個程序,在一個無序數組中查找一個特定的值。要求程序的時間復雜度為 O(log n)。”
在本題的回答中,文心一言沒有準確理解到時間復雜度O(log n)的需求,GPT-3.5及GPT-4給出的代碼為二分法搜索,只有在面對有序數組時才能滿足時間復雜度要求,也非最佳答案。整體來看,三個模型在代碼生成方面均有較大的改進空間,GPT-3.5 與 GPT-4 表現基本持平,略優于文心一言。
圖:文心一言的回答

來源:國金證券
樂思輿情系統的AI助理調用GPT-3.5的回答:


圖:GPT-4的回答

來源:國金證券
3.2 算力—GPU
大模型即“大算力+強算法+大數據”結合的產物。算力是訓練大模型的底層動力源泉,一個優秀的算力底座在大模型的訓練和推理具備效率優勢;AI服務器是算力的底層載體,包含CPU、GPU、內存、硬盤、網卡等。
圖 服務器成本構成

如上圖,在AI服務器中,AI芯片在大模型訓練中成本最高,同時AI芯片是AI算力的“心臟”。人工智能深度學習需要異常強大的并行處理能力,GPU相比于CPU更擅長于并行計算能力,正在大放異彩。根據IDC的數據,2021年H1中國AI芯片,GPU占比最多為91.90%。
GPU服務器超強的計算功能可應用于海量數據處理方面的運算,如搜索、大數據推薦、智能輸入法等。此外,GPU可作為深度學習的訓練平臺,GPU服務器可直接加速計算服務,亦可直接與外界連接通信。
3.2.1 GPT-4:從A100到H100
3.2.1.1 英偉達A100
從2012年卷積神經網絡AlexNet,到最近的ChatGPT,背后都離不開英偉達的算力支持。AlexNet使用的是英偉達GTX 580進行訓練,而OpenAI訓練ChatGPT所用到的A100芯片算力已經達到當年的100萬倍。
當前唯一可以實際處理ChatGPT的GPU是英偉達HGX A100,OpenAI就是使用A100 GPU訓練和運行ChatGPT的。
圖:英偉達NVIDIA HGX A100

NVIDIA A100 Tensor Core GPU 可針對 AI、數據分析和 HPC 應用場景,在不同規模下實現出色的加速,有效助力更高性能的彈性數據中心。A100 的性能比上一代產品提升高達20 倍,并可劃分為七個GPU 實例,以根據變化的需求進行動態調整。
A100 提供 40GB 和 80GB 顯存兩種版本,A100 80GB 將 GPU 顯存增加了一倍,對于具有龐大數據表的超大型模型(例如深度學習推薦模型 [DLRM]),A100 80GB 可為每個節點提供高達1.3TB的統一顯存,而且吞吐量比 A100 40GB 多高達 3 倍。
圖 針對大型模型提供高達 3 倍的 AI 訓練速度

3.2.1.2 英偉達H100
3月21日,在英偉達舉辦的年度GTC開發者大會上,其CEO黃仁勛發表了名為《切勿錯過AI的決定性時刻》(Don’t Miss This Defining Moment in AI)的演講,在長達78分鐘的視頻中,他四次用“iPhone時刻”來形容AI當下的發展,并稱“這將是我們迄今為止最重要的一次GTC大會”。
針對算力需求巨大的ChatGPT,英偉達發布了NVIDIA H100 NVL,它是基于去年已經發布的H100的改進版本,是一種具有94GB內存和加速Transformer引擎的大語言模型(LLM)專用解決方案,配備了雙GPU NVLINK的PCIE H100 GPU。外界直呼:這是“核彈芯片”級別的產品。
黃仁勛表示,H100 GPU的處理速度比之前的A100 GPU快十倍,可以將大語言模型的處理成本降低一個數量級。
圖 英偉達H100 NVL GPU

3.2.1.3 算力平民化—DGX Cloud
另外,英偉達還聯合微軟Azure、Google GCP和Oracle OCI三家云廠商合作推出了DGX Cloud。普通企業想要訓練大語言模型,可以直接租賃DGX云服務,將英偉達DGX AI超級計算機實時接入公司,以滿足高級AI訓練性能要求;即DGX Cloud將把 DGX AI超級計算機“通過瀏覽器引入每一家企業”。
英偉達提供的DGX服務器,包含8個H100或A100圖形處理器和640GB內存,A100層的價格為每月36999美元。相比之下,直接購買一個實體DGX服務器,需要20萬美元;微軟訓練新必應Bing更是花費數億美元購買了數萬個A100芯片。
圖:英偉達DGX云服務

3.2.2 文心一言:昆侖芯
昆侖芯科技戰略負責人宋春曉證實,人工智能芯片是算力的核心,昆侖芯二代已在百度文心大模型的應用中廣泛導入,并為各行各業的智能化升級提供AI算力支持。
基于新一代自研架構昆侖芯XPU-R而設計,聚焦高性能、通用性和易用性。相比1代產品,昆侖芯2代AI芯片的通用計算核心算力提升2-3倍,可為數據中心高性能計算提供強勁AI算力。
圖 昆侖芯2代AI芯片

3.3 訓練數據
3.3.1 GTP-4
OpenAI首席執行官Sam Altman接受公開采訪指出,GTP-4參數量為GTP-3的20倍,需要的計算量為GTP-3的10倍;GTP-5在2024年底至2025年發布,它的參數量為GTP-3的100倍,需要的計算量為GTP-3的200-400倍。
圖 GPT系列模型的數據量和參數量

3.3.2 文心一言
百度 CEO 李彥宏在發布會上介紹,文心一言是百度新一代知識增強大語言模型,它基于百度 ERNIE 及 PLATO 系列模型的基礎進行研發,其大模型的訓練數據包括萬億級網頁數據、數十億的搜索數據和圖片數據、百億級的語音日均調用數據,以及 5500 億事實的知識圖譜等。
早在2019年,百度開發的知識增強語義理解模型ERNIE就登頂了全球權威數據集GLUE榜單,并刷新榜單歷史。現在,該模型已更新迭代至文心ERNIE 3.0,參數規模高達2600億,幾乎比谷歌LaMDA(1350萬)高了一倍,也高于GPT-3 (1750萬),是全球最大的中文單體模型。
目前,GTP-4參數量為GTP-3 (1750萬)的20倍,即3.5萬億,遠高于文心ERNIE 3.0的2600億,不過,李彥宏近日在極客公園的直播中表示,文心一言確實不如現在最好的ChatGPT版本,但差距也不是很大,可能就是一兩個月的差別。文心一言提升速度不慢,但ChatGPT本身也在不斷升級,目前差不多是ChatGPT今年1月份的水平。
3.4 商業化
3.4.1 ChatGPT
2023年2月初,僅僅正式上線2個月的ChatGPT超過Tiktok,成為互聯網歷史上最快突破1億月活的應用。為了達成這個小目標,Tiktok用了9個月,再之前的Facebook花了42月之久。
圖 達1億用戶所用時間

3.4.2 文心一言
3月24日,百度集團副總裁袁佛玉表示,憑借文心一言的優勢,百度智能云有可能成為云計算市場第一。她還首次披露,文心一言新聞發布會后5天,預約測試用戶已經超過100萬,申請文心一言API調用服務測試的企業超過10萬家。
4、小結
目前看,無論是輿情還是技術實力,百度相比GPT-4 都占了下風,而輿論的弱勢是由于技術實力和模型功能的弱勢導致的。大家驚艷于GPT-4的強大功能,對GPT-4提高生產效率的眾多功能表示好奇和支持,也對自己的職業將被替代感到焦慮,許多國內網友還對不能使用GPT-4 感到氣憤,發表許多冷嘲熱諷的觀點。
當文心一言剛發布的3月16日,輿論以失望、群嘲、調侃為主,一些是作為全村希望的文心一言比不過GPT-4 的恨鐵不成鋼;一些是對百度有偏見,因為壟斷多年的百度搜索給用戶的體驗并不好,于是一些人感性的認為百度做什么都垃圾;一些輿論則指向了國產和自主創新,極端的認為國外一開源國內就創新、國外負責智能,百度負責人工。隨著發布會結束,大家逐漸體驗文心一言之后,對其功能有了更全面的認識,負面輿論也在不斷減少,百度畢竟是世界上第二個做出來的觀點成為共識,網友紛紛表示給百度一點時間。無論GPT-4還是文心一言,無論商業領袖還是普通網民,無論產業界還是資本市場,大家已經對AI即將快速商業化形成共識,未來是人工智能的時代。
]]>